
DiffRhythm 是一款新型 AI 音乐生成模型,能在 10 秒内生成长达 4 分 45 秒的完整歌曲,包含人声和伴奏。它采用简单高效的全 diffusion 架构,仅需歌词和风格提示即可创作,还支持本地部署,最低只需 8G 显存。
音乐创作,尤其是完整歌曲的生成,一直是人工智能领域的一大挑战。
Suno、Udio 等商用音乐生成大模型展现出惊人的音乐生成能力。但现有开源的音乐生成模型要么只能生成人声或伴奏,要么依赖复杂的多阶段架构,难以扩展到长音频生成。
而现在,AI 音乐破局时刻到了!
近日,西北工业大学音频语音与语言处理实验室(ASLP@NPU)和香港中文大学(深圳)的研究团队提出了一种名为 DiffRhythm(中文名:谛韵)的新型音乐生成 AI 模型,全 diffusion 架构,它能够在短短 10 秒内生成长达 4 分 45 秒的不同风格完整双轨高保真歌曲,包含人声和伴奏!
最低仅需 8G 显存,可本地部署到消费级显卡!

在线 Demo: https://huggingface.co/spaces/ASLP-lab/DiffRhythm
Paper: https://arxiv.org/abs/2503.01183
Github: https://github.com/ASLP-lab/DiffRhythm
Hugging Face: https://huggingface.co/ASLP-lab/DiffRhythm-base
这一成果不仅刷新了音乐生成的速度,还大大简化了生成流程,让音乐创作变得更加高效和便捷。模型完全采用华为昇腾 910B 训练,同时支持N卡。
目前模型和推理代码全部开源。开源短短几天位列 Hugging Face Space 趋势榜第一和总榜第五,受到众多网友和音乐爱好者广泛好评。

DiffRhythm:简单、快速、高质量
DiffRhythm 的核心优势在于它的简洁性和高效性。在模型方面它摒弃了复杂的多阶段架构,采用了一个简单的基于 LLaMA 的 DiT,只需要歌词和风格提示即可生成歌曲。
这种非自回归结构确保了快速的推理速度,相比现有的语言模型方法,DiffRhythm 的速度提升显著,更适合实时应用和用户交互。在数据方面,仅需音频与对应歌词,无需复杂数据处理标注流程,易于 scale up 到大数据。
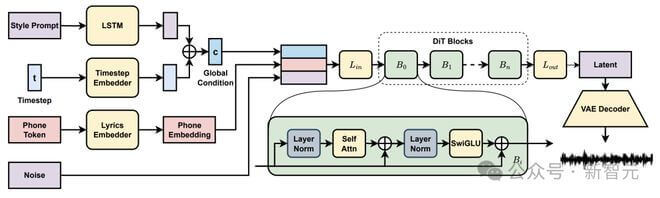
DiffRhythm 以歌词和风格提示输入,生成 44.1kHz 采样率全长立体声音乐作品(最长 4 分 45 秒)。
DiffRhythm 由两个顺序训练的模型组成:1) 变分自编码器 (VAE),学习音频波形的紧凑潜在表示,使得分钟级长音频建模成为可能;2) DiT 建模 VAE 的潜在空间,通过迭代去噪生成歌曲。
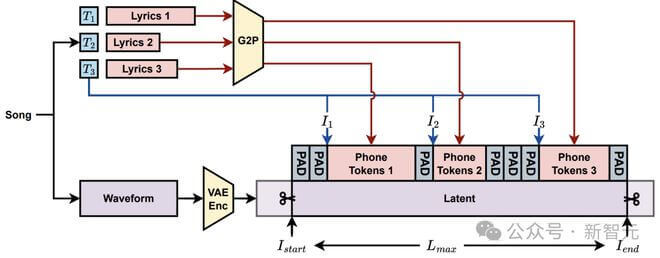
句级歌词对齐
在歌曲生成中,歌词与歌声的对齐是一个极具挑战性的问题,可以概括为以下两个方面:
时间上的不连续性:歌词中的句子之间往往存在较长的间隔,这些间隔可能是纯音乐部分,导致歌词与歌声之间的时间对应关系不连续。
伴奏的干扰:相同的一个字,在不同歌曲中的伴奏不同,唱法也不同,这使得歌声的对齐更加复杂。
为了解决这些问题,DiffRhythm 提出了一种句子级对齐机制。具体来说,该机制仅依赖于句子起始时间的标注,通过以下步骤实现歌词与歌声的对齐:
句子分割与音素转换:首先,将歌词按照句子分割,并通过 Grapheme-to-Phoneme (G2P) 转换将每个句子转换为音素序列。
初始化潜在序列:创建一个与潜在表示长度相同的序列,并用填充符号( )初始化。
对齐音素与潜在表示:根据歌词句子的起始时间戳,将音素序列映射到潜在表示的对应位置。例如,如果一个句子的起始时间是 10 秒,那么对应的音素序列将被放置在潜在表示的第 10 秒位置。
通过这种方式,DiffRhythm 只需要句子起始时间的标注,即可实现歌词与歌声的对齐。
压缩鲁棒 VAE
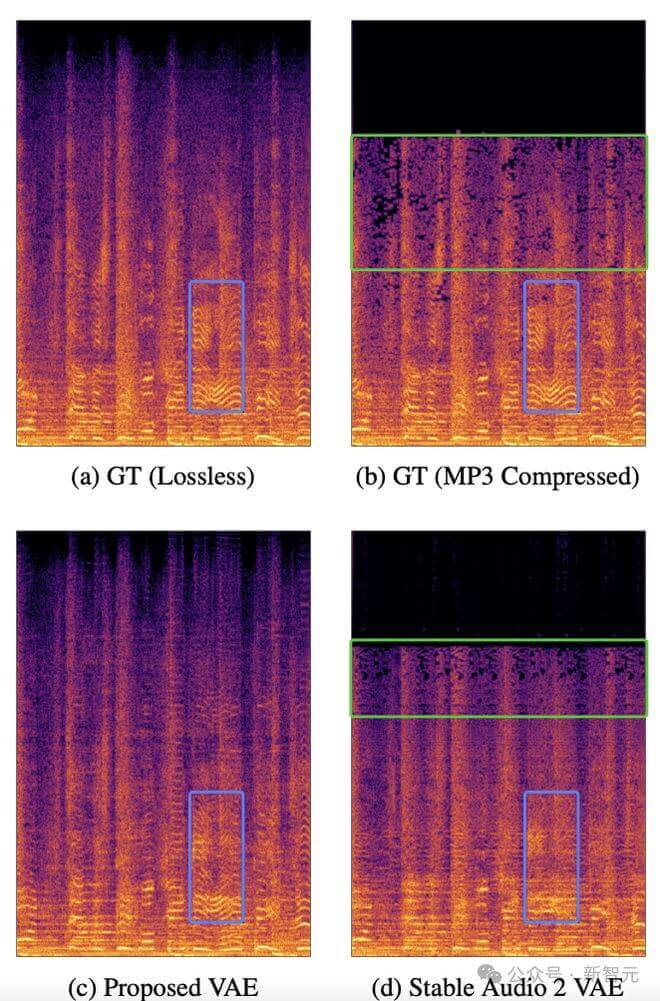
考虑到大量歌曲数据都以压缩后的 MP3 格式存在,而高频细节在压缩过程中会受到损害,我们采用数据增强来赋予 VAE 修复功能。
具体来说,VAE 以无损 FLAC 格式数据进行训练,其中输入经过 MP3 压缩,而重建目标仍然是原始无损数据。通过这种有损到无损的重建过程,VAE 学会将从有损压缩数据中得出的潜在表示解码回无损音频信号。
实验结果
DiffRhythm 的表现令人印象深刻。在音频重建方面,它在无损和有损压缩条件下都优于现有的基线模型。

在可视化分析中,可以看到 DiffRhythm VAE 可以有效修复 MP3 压缩损失
在歌曲生成方面,DiffRhythm 的生成歌曲在音质、音乐性和歌词可理解性上都表现出色,与现有的 SongLM 模型相比,DiffRhythm 的歌词清晰度更高,推理速度更快。

未来展望
尽管 DiffRhythm 已经可以快速生成整首歌曲,但仍有进一步优化的空间。例如,未来可能会通过在训练中引入随机掩码来支持对生成歌曲的特定片段进行编辑。
此外,DiffRhythm 未来可能会引入自然语言条件机制,以实现更精细的风格控制,从而无需依赖音频参考。
参考资料:https://arxiv.org/abs/2503.01183
来自: 网易科技

